Ceph分布式存储—从入门到实战
Ceph是什么,为什么要用它?
在开始学习Ceph之前,我们先来复习一下存储相关知识
存储类型
集中式存储
集中式存储是一种传统的存储模式,所有存储资源集中在一台或少量存储设备中。
特点:
存储设备通常是 SAN(存储区域网络)或 NAS(网络附加存储)。
数据的管理和访问由专用存储控制器集中控制。
性能强大,但存在单点故障和扩展性限制的问题。
适用场景:
小型或中型应用场景,需要简单可靠且易于管理的存储解决方案。
分布式存储
分布式存储是一种现代的存储架构,数据分布在多个节点上,以提供更高的可用性和扩展性。
特点:
数据被切分成多个副本或块,存储在多个物理节点上。
无单点故障,支持横向扩展,成本更低。
更适合现代云计算和大数据的需求。
适用场景:
云服务、大数据、容器持久化应用存储等场景。
了解Ceph
Ceph 是一个开源的分布式存储系统,通过其高扩展性、可靠性和灵活性,满足了云计算、大数据等多种复杂场景的需求。它的统一存储特性和高性能、高可靠性和高扩展性特质使其成为企业部署存储的首选之一。
Ceph的架构设计
NFS
传统上我们常用的存储服务有NFS,为什么不用NFS呢?
设想一下,我们有一个NFS节点,如果这个NFS节点挂掉了,我们把硬盘拔下来,在其他节点上重新部署一个NFS服务,那么数据依然是可以恢复的,但如果挂掉的不是节点而是硬盘呢?到这里你可能想到了给磁盘做RAID提供数据冗余,OK,保留这个问题,继续研究。
MosseFS
MosseFS就是一个分布式存储,他的技术架构是提供一个Master节点,用来管理整个集群,Client只需要通过挂载到Master节点就可以往集群内存储文件。
一个文件是由文件元数据和文件数据组成的,文件元数据保存的是这个文件的描述信息,例如文件大小、文件权限、读写时间等等,这些数据一般不大,所以会直接保存在Master节点中,而文件本身数据则会以多副本形式存储在各个存储节点中,所以这就实现了存储的可靠性。
虽然文件的元数据不大,但在这个海量数据时代,当元数据过多时,Master就成了整个集群的瓶颈,因为所有文件的请求都会经过Master处理,而且MooseFS不支持Master高可用,虽然我们可以给两个Master通过Keepalive提供VIP的形式实现,但在同一时间内只有一个Master在工作,所以瓶颈依然存在。
GlusterFS
为了避免Master瓶颈,GlusterFS采用了去Master架构,即在每个存储节点上都内嵌一个可以代替Master的组件,这样所有的元数据并不是存放在同一个节点上,而是每个存储节点都保存了部分元数据,但新的问题出现了,使用MosseFS时,Client通过挂载Master节点即可实现存储文件,但现在没有Master了,或者每个节点都是Master了,客户端应该如何挂载文件服务呢?
GlusterFS提供了一个Gluster-Client软件,要求所有客户端安装,并在软件中配置所有存储节点的IP。这样不仅客户端使用非常麻烦,也增加了后期运维工作的复杂度。下面我们来看看主角Ceph是怎么做的。
Ceph
MosseFS的Master节点容易瓶颈,而GlusterFS客户端操作复杂,Ceph与前两者不同,采用了折中方案,它保留了Master节点,但在Master节点中不保存文件元数据,而是保存集群元数据,也就是保存集群的信息,那文件元数据去哪了呢,Ceph提供了专门的文件元数据节点,这个节点只负责保存文件元数据,不提供其他服务。这样一来即解决了Master瓶颈问题,也简化了客户端操作复杂度。
这就是Ceph的架构,它兼顾了易用、易维护、可靠性和效率,这就是它流行的原因。
现在再回头想一下NFS的问题,为什么不使用硬件RAID呢,很简单,因为硬件RAID的扩展性差,同时成本也比分布式存储高太多了。
Ceph的存储过程
Ceph组件
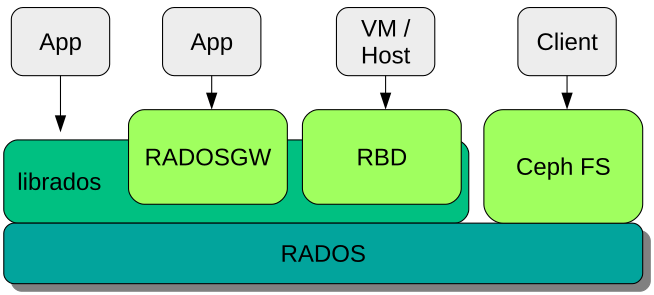
核心组件(RADOS)
MON:集群监视器(即Master),监控整个集群状态,保证集群数据一致性。
OSD:集群存储节点,处理集群数据的复制、恢复、回填、再均衡,并向其他osd守护进程发送心跳,然后向Monitor提供监控信息。
MGR:集群管理器,负责监控集群运行指标和集群状态,如存储使用率,系统负载。
可选组件(各类文件服务网关)
MDS:元数据节点,为CephFS提供元数据计算、缓存与同步。只有使用CephFS时,才启用该组件。
RADOSGW:对象存储网关
RBD:块设备存储接口
NFS-Genasha:NFS服务发布
Ceph存储结构
Ceph中一切皆对象,不管是RBD块存储接口,RGW对象存储接口还是文件存储CephFS接口,其存储如到Ceph中的数据均可以看作是一个对象,一个文件需要切割为多个对象(object),每个 Object 会先通过简单的 Hash 算法归到一个 PG 中,PGID 再作为入参通过 CRUSH计算置入到多个OSD中(这里 Object 可以看作是文件,PG 即是一个目录,OSD 是一个数据根目录下仅有一级子目录的简易文件系统)。
这些切割后的对象怎么选择到对应的OSD存储节点呢,这需要依赖于Ceph的智能调度算法CRUSH,通过CRUSH算法将对象调度到合适的OSD节点上,不管是客户端还是OSD,均使用CRUSH算法来计算对象在集群中OSD的位置信息,同时保障object的副本能落到合适的OSD节点上。
Ceph存储过程
文件切割成4M大小的数据对象
数据对象通过hash算法找到存储池中的pg
在通过crush算法找到pg映射的osd
pg中的主osd将对象写入到磁盘
主osd将数据同步给备份osd,并等到备份osd写完后返回确认消息
主osd将写完信息告知客户端
Ceph规划
网络规划
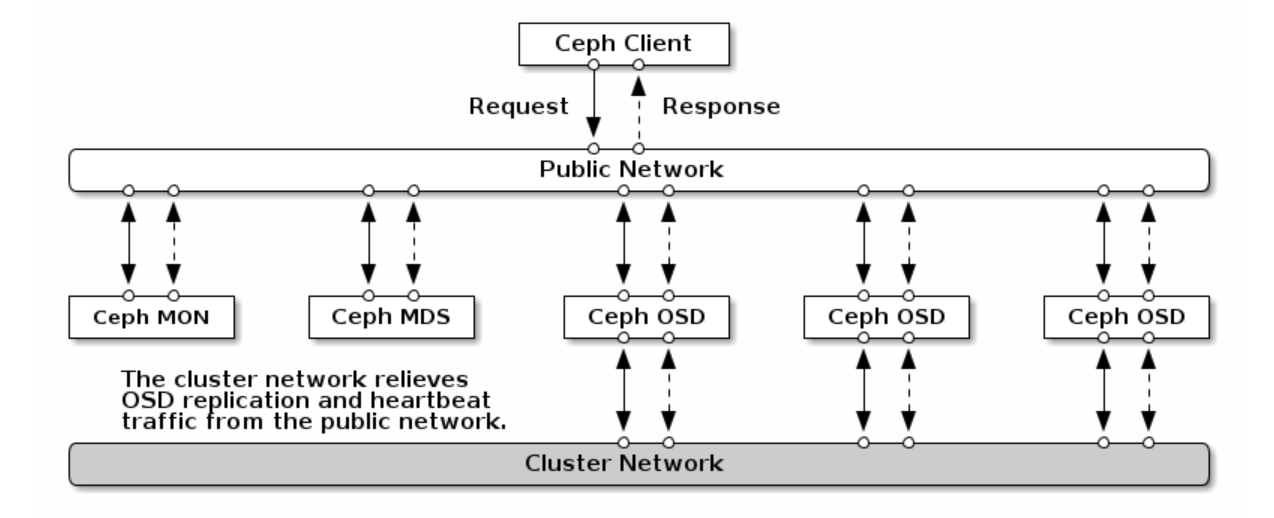
公共网络是 Ceph 守护进程相互之间以及与其客户端之间进行通讯的网络。这意味着所有 Ceph 集群流量都通过该网络传输(配置集群网络时除外)。
集群网络是 OSD 节点之间的后端网络,用于执行复制、重新平衡和恢复操作。如果配置了此可选网络,则理想情况下,它将提供两倍于公共网络的带宽(默认为三向复制),因为主 OSD 会通过此网络向其他 OSD 发送两个副本。公共网络位于客户端和网关之间,用于在其中一端与 Monitor、Manager、MDS 节点、OSD 节点进行通讯。Monitor、Manager 和 MDS 节点也会使用该网络与 OSD 节点进行通讯。
硬件规划
存储节点容量应当平均分布,例如3个OSD节点,则每个节点不超过总容量的35%左右
规划总容量时,考虑到即使一个节点长期离线,已用总容量不应超过80%
MON、MGR、MSD/网关节点应考虑独立分布在不同节点上以实现更高的可靠性
IOPS 密集型场景
OSD:每个 NVMe SSD 上配置四个 OSD(可以使用 lvm)。
日志:存放于 NVMe SSD。
Controller:使用 Native PCIe 总线。
网络:每 12 个 OSD 配置一个万兆网口。
内存:最小 12G,每增加一个 OSD 增加 2G 内存。
CPU:每个 NVMe SSD 消耗 10 CPU Cores。
高吞吐量型场景
OSD: 使用 7200 转速的机械盘,每个磁盘为一个 OSD。不需要配置 RAID。
日志:如果使用 SATA SSD,日志容量与 OSD 容量的比率为 1:4-5。如果使用 NVMe SSD,则容量比率为 1:12-18。
网络:每 12 个 OSD 配置一个万兆网口。
内存:最小 12G,每增加一个 OSD 增加 2G 内存。
CPU:每个 HDD 消耗 0.5 CPU Cores。
高容量型场景
OSDs: 使用 7200 转速的机械盘,每个磁盘为一个 OSD。不需要配置 RAID。
日志:使用 HDD 磁盘。
网络:每 12 个 OSD 配置一个万兆网口。
内存:最小 12G,每增加一个 OSD 增加 2G 内存。
CPU:每个 HDD 消耗 0.5 CPU Cores。
最佳实践配置
OSD
OSD:1 per HDD = 12 OSD
CPU:0.5 Cores per HDD = 6 Cores
RAM:1GB+4GB per OSD = 64GB
磁盘:
4TB SAS HDD * 12 = 48T(DATA,JBOD/单盘RAID0)
960GB SSD * 2 (OS,RAID1)
960GB SSD * 2 (WAL+DB,RAID1)
MON、MGR、MDS、RADOSGW
CPU:8 Cores
RAM:16 GB
磁盘:960GB SSD * 2 (OS,RAID1)
Ceph演示环境部署
版本:Centos7.9 + Ceph-Deploy + Ceph 14 (Nautilus )
环境信息
部署准备
(ALL)关闭防火墙与selinux
systemctl stop firewalld systemctl disable firewalld setenforce 0 sed -i 's/enforcing/disabled/' /etc/selinux/config(ALL)配置hosts解析
cat >> /etc/hosts << EOF 172.16.30.141 ceph01 172.16.30.142 ceph02 172.16.30.143 ceph03 172.16.30.144 ceph04 EOF(ALL)配置ntp同步
crontab -e */5 * * * * /usr/sbin/ntpdate time1.aliyun.com &> /dev/null && hwclock -w &> /dev/null(ALL)配置yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo # 安装ceph nautilus镜像源 yum -y install https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/ceph-release-1-1.el7.noarch.rpm # 手动替换为阿里源 sed -i 's/download.ceph.com/mirrors.aliyun.com\/ceph/g' /etc/yum.repos.d/ceph.repo(管理节点)配置免密登录
ssh-keygen ssh-copy-id -i .ssh/id_rsa.pub ceph01 ssh-copy-id -i .ssh/id_rsa.pub ceph02 ssh-copy-id -i .ssh/id_rsa.pub ceph03 ssh-copy-id -i .ssh/id_rsa.pub ceph04(管理节点)部署依赖
yum install -y python-setuptools python-pip(管理节点)安装ceph-deploy
yum install -y https://mirrors.aliyun.com/ceph/rpm-nautilus/el7/noarch/ceph-deploy-2.0.1-0.noarch.rpm
开始部署
(ALL)创建工作目录
mkdir -p /etc/ceph(管理节点)初始化MON节点
cd /etc/ceph # 初始化配置,指定集群网段和存储网段 ceph-deploy new --public-network 172.16.30.0/24 --cluster-network 192.168.30.0/24 ceph01 [root@ceph01 ceph]# ll total 12 -rw-r--r-- 1 root root 263 Nov 25 14:29 ceph.conf -rw-r--r-- 1 root root 3037 Nov 25 14:29 ceph-deploy-ceph.log -rw------- 1 root root 73 Nov 25 14:29 ceph.mon.keyring # 整个集群的admin管理密钥文件,一定要保管好此文件 # 在mon节点手动安装ceph-mon yum -y install ceph-mon # 初始化mon节点,如果多个mon节点可以批量初始化 ceph-deploy mon create ceph01 # 初始化并覆盖配置 ceph-deploy --overwrite-conf mon create-initial # 检查服务状态 [root@ceph01 ceph]# ps -ef |grep ceph-mon ceph 16368 1 0 14:32 ? 00:00:00 /usr/bin/ceph-mon -f --cluster ceph --id ceph01 --setuser ceph --setgroup ceph root 16782 14547 0 14:35 pts/0 00:00:00 grep --color=auto ceph-mon(管理节点)初始化MGR节点
# 手动安装mgr服务 yum -y install ceph-mgr # 初始化mgr节点,如果多个mgr节点可以批量初始化 ceph-deploy mgr create ceph01 # 检查服务状态 [root@ceph01 ceph]# ps -ef |grep ceph-mgr ceph 16896 1 10 14:42 ? 00:00:01 /usr/bin/ceph-mgr -f --cluster ceph --id ceph01 --setuser ceph --setgroup ceph root 17017 14547 0 14:43 pts/0 00:00:00 grep --color=auto ceph-mgr(管理节点)初始化OSD节点
# 给所有存储节点安装ceph环境 ceph-deploy install --no-adjust-repos --nogpgcheck ceph0{2..4}(管理节点)添加存储磁盘
# 列出所有存储节点的磁盘信息 ceph-deploy disk list ceph0{2..4} # 逐个节点擦除用于创建OSD的磁盘,注意区分系统盘 ceph-deploy disk zap ceph02 /dev/sdb #/dev/sdc /dev/sdd .... ceph-deploy disk zap ceph03 /dev/sdb ceph-deploy disk zap ceph04 /dev/sdb(管理节点)创建OSD
# 添加OSD时可以选择将db、wal和数据文件分别存放至SSD和HDD以获取最大性能 # ceph-deploy osd create {node} --data /path/to/data --block-db /path/to/nvme --block-wal /path/to/ssd # 由于这里是测试环境,直接把所有文件都存放在HDD测试磁盘中,逐个节点逐个磁盘创建OSD ceph-deploy osd create ceph02 --data /dev/sdb ceph-deploy osd create ceph03 --data /dev/sdb ceph-deploy osd create ceph04 --data /dev/sdb # 检查集群状态 [root@ceph01 ceph]# ceph -s cluster: id: 354efb66-ec87-4c13-8288-9ab44973a161 health: HEALTH_WARN mon is allowing insecure global_id reclaim # 这里有个告警,稍候处理 services: mon: 1 daemons, quorum ceph01 (age 84m) mgr: ceph01(active, since 73m) osd: 3 osds: 3 up (since 55s), 3 in (since 55s) # 可以看到三个OSD已经上线 task status: data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 3.0 GiB used, 57 GiB / 60 GiB avail pgs: # 禁用不安全模式,关闭告警 ceph config set mon auth_allow_insecure_global_id_reclaim false
挂载服务
1.RBD(块存储)
创建RBD存储池
# 创建存储池命令格式(默认是replicated 副本模式) # ceph osd pool create {pg_num} {pgp_num} (replicated|erasure) # Ceph 推荐的 PG 数量计算公式是:PG 数量=总OSD数×100/副本数 # 创建存储池 ceph osd pool create myrbd1 64 64 # 对存储池启用RBD服务 ceph osd pool application enable myrbd1 rbd # rbd初始化存储池 rbd pool init -p myrbd1 [root@ceph01 ceph]# ceph df RAW STORAGE: CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 60 GiB 57 GiB 8.6 MiB 3.0 GiB 5.02 TOTAL 60 GiB 57 GiB 8.6 MiB 3.0 GiB 5.02 # 存储池已经创建完毕 POOLS: POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL myrbd1 1 128 19 B 1 192 KiB 0 18 GiB创建镜像
# 创建一个大小为10G,支持克隆+快照的layering镜像 rbd create myimg1 --size 10G --pool myrbd1 --image-format 2 --image-feature layering [root@ceph01 ceph]# rbd ls --pool myrbd1 myimg1 # 查看镜像信息 [root@ceph01 ceph]# rbd --image myimg1 --pool myrbd1 info rbd image 'myimg1': size 10 GiB in 2560 objects order 22 (4 MiB objects) snapshot_count: 0 id: 10644dfe40b8 block_name_prefix: rbd_data.10644dfe40b8 format: 2 features: layering op_features: flags: create_timestamp: Mon Nov 25 18:40:56 2024 access_timestamp: Mon Nov 25 18:40:56 2024 modify_timestamp: Mon Nov 25 18:40:56 2024 # 镜像缩扩容\快照\回收等操作在这里不做演示,有需要可查询官网文档客户端挂载存储
# 在需要挂载的客户端中,安装ceph-common组件 yum -y install ceph-common # 同步认证文件到客户端。(这里使用了admin权限,也可以在管理节点中创建普通用户下发给客户端) scp /etc/ceph/ceph.conf /etc/ceph/ceph.client.admin.keyring 172.16.30.135:/etc/ceph # 客户端挂载rbd设备镜像 [root@huggingface-cli ~]# rbd -p myrbd1 map myimg1 /dev/rbd0 [root@huggingface-cli ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sr0 11:0 1 1024M 0 rom vda 252:0 0 80G 0 disk ├─vda1 252:1 0 1G 0 part /boot └─vda2 252:2 0 78G 0 part ├─centos-root 253:0 0 70G 0 lvm / └─centos-swap 253:1 0 8G 0 lvm [SWAP] rbd0 251:0 0 10G 0 disk # 后续可直接对rbd0设备进行格式化、挂载、测速等 [root@huggingface-cli test]# dd if=/dev/zero of=test.1G bs=1M count=9999 9999+0 records in 9999+0 records out 10484711424 bytes (10 GB) copied, 69.9138 s, 150 MB/s # 卸载rbd设备 rbd unmap /dev/rbd0 # ceph集群删除rbd镜像 [root@ceph01 ceph]# rbd status -p myrbd1 --image myimg1 Watchers: watcher=172.16.30.135:0/3002798135 client.4218 cookie=18446462598732840961 [root@ceph01 ceph]# rbd status -p myrbd1 --image myimg1 Watchers: none [root@ceph01 ceph]# rbd ls -l -p myrbd1 NAME SIZE PARENT FMT PROT LOCK myimg1 10 GiB 2 [root@ceph01 ceph]# rbd trash move -p myrbd1 --image myimg1 [root@ceph01 ceph]# rbd trash list -p myrbd1 10644dfe40b8 myimg1 [root@ceph01 ceph]# rbd trash remove -p myrbd1 --image-id 10644dfe40b8 Removing image: 100% complete...done.
2.RADOSGW(S3对象存储)
安装ceph-radosgw
# 所有radosgw节点安装 yum install -y ceph-radosgw # 管理节点创建rgw守护进程 ceph-deploy --overwrite-conf rgw create ceph01 #更改监听端口(Civetweb 默认监听在 7480 端口并提供 http 协议) [root@ceph01 ceph]# vim ceph.conf .... [client.rgw.ceph01] #ceph01是启动时的主机名 rgw_host = ceph01 rgw_frontends = civetweb port=10000 num_threads=600 request_timeout_ms=70000 log file = /var/log/ceph/client.rgw.rgwweb1.log #rgw_host:对应的RadosGW名称或者IP地址 #rgw_frontends:这里配置监听的端口,是否使用https,以及一些常用配置: 1、port:如果是https端口,需要在端口后面加一个s。 2、ssl_certificate:指定证书的路径。 3、num_threads:最大并发连接数,默认为50,根据需求调整,通常在生产集群环境中此值应该更大 4、request_timeout_ms:发送与接收超时时长,以ms为单位,默认为30000 5、access_log_file:访问日志路径,默认为空 6、error_log_file:错误日志路径,默认为空 #修改完 ceph.conf 配置文件后需要重启对应的 RadosGW 服务,再推送配置文件 [root@ceph01 ceph]# ceph-deploy --overwrite-conf config push ceph0{1..3} #每个rgw节点重启rgw服务 [root@ceph01 ceph]# systemctl restart ceph-radosgw.target # 检查radosgw服务状态 [root@ceph01 ceph]# ps -ef |grep radosgw ceph 25442 1 0 11:43 ? 00:00:00 /usr/bin/radosgw -f --cluster ceph --name client.rgw.ceph01 --setuser ceph --setgroup ceph root 26230 14547 0 11:46 pts/0 00:00:00 grep --color=auto radosgw创建radosgw账户
# 在管理节点通过radosgw-admin创建用户 [root@ceph01 ceph]# radosgw-admin user create --uid="rgwuser" --display-name="rgw access user" { "user_id": "rgwuser", "display_name": "rgw access user", "email": "", "suspended": 0, "max_buckets": 1000, "subusers": [], "keys": [ { "user": "rgwuser", "access_key": "32OZQMMWGHK6ZK4OZSM9", "secret_key": "gqYCeEqmcT3dRDQOOkiNGWiDvdBCbzcmjRPkNRzy" } ], "swift_keys": [], "caps": [], "op_mask": "read, write, delete", "default_placement": "", "default_storage_class": "", "placement_tags": [], "bucket_quota": { "enabled": false, "check_on_raw": false, "max_size": -1, "max_size_kb": 0, "max_objects": -1 }, "user_quota": { "enabled": false, "check_on_raw": false, "max_size": -1, "max_size_kb": 0, "max_objects": -1 }, "temp_url_keys": [], "type": "rgw", "mfa_ids": [] } # 输出中的access_key和secret_key就是我们要获取的凭证 # 也可以通过以下命令查询用户信息 radosgw-admin user info --uid="rgwuser"客户端挂载radosgw
# 客户端安装s3命令工具 yum -y install s3cmd # 生成配置文件,注意跳过认证和测试步骤 s3cmd --configure # 修改配置文件 vim /root/.s3cfg access_key = xxx secret_key = xxx host_base = 172.16.30.141:10000 host_bucket = "" use_https = False # 测试创建存储桶 [root@huggingface-cli mnt]# s3cmd mb s3://test Bucket 's3://test/' created # 上传文件 [root@huggingface-cli ~]# s3cmd put www.tar.gz s3://test upload: 'www.tar.gz' -> 's3://test/www.tar.gz' [1 of 1] 11953503 of 11953503 100% in 3s 3.36 MB/s done # 查看文件 [root@huggingface-cli ~]# s3cmd ls s3://test 2024-11-26 06:07 11953503 s3://test/www.tar.gz # 删除文件 [root@huggingface-cli ~]# s3cmd del s3://test/www.tar.gz delete: 's3://test/www.tar.gz'
3.MDS(CephFS)
安装ceph-mds
# 所有mds节点安装 yum install -y ceph-mds # 管理节点初始化mds服务 ceph-deploy mds create ceph01 # 检查服务状态 [root@ceph01 ceph]# ps -ef |grep mds ceph 27598 1 0 14:16 ? 00:00:00 /usr/bin/ceph-mds -f --cluster ceph --id ceph01 --setuser ceph --setgroup ceph root 27691 14547 0 14:17 pts/0 00:00:00 grep --color=auto mds # 创建cephfs存储池 [root@ceph01 ceph]# ceph osd pool create cephfs-matedata 32 32 pool 'cephfs-matedata' created [root@ceph01 ceph]# ceph osd pool create cephfs-data 64 64 pool 'cephfs-data' created # 创建并查看cephfs [root@ceph01 ceph]# ceph fs new mycephfs cephfs-matedata cephfs-data new fs with metadata pool 8 and data pool 9 [root@ceph01 ceph]# ceph fs ls name: mycephfs, metadata pool: cephfs-matedata, data pools: [cephfs-data ] # 查看mds状态,当前mds工作节点为ceph01 [root@ceph01 ceph]# ceph mds stat mycephfs:1 {0=ceph01=up:active} # 查看cephfs状态 [root@ceph01 ceph]# ceph fs status mycephfs mycephfs - 0 clients ======== +------+--------+--------+---------------+-------+-------+ | Rank | State | MDS | Activity | dns | inos | +------+--------+--------+---------------+-------+-------+ | 0 | active | ceph01 | Reqs: 0 /s | 10 | 13 | +------+--------+--------+---------------+-------+-------+ +-----------------+----------+-------+-------+ | Pool | type | used | avail | +-----------------+----------+-------+-------+ | cephfs-matedata | metadata | 1536k | 35.8G | | cephfs-data | data | 0 | 35.8G | +-----------------+----------+-------+-------+ +-------------+ | Standby MDS | +-------------+ +-------------+ MDS version: ceph version 14.2.22 (ca74598065096e6fcbd8433c8779a2be0c889351) nautilus (stable)客户端挂载cephfs
# 管理节点查看admin管理秘钥(这里使用了admin权限,也可以在管理节点中创建普通用户下发给客户端) [root@ceph01 ceph]# cat ceph.client.admin.keyring [client.admin] key = AQDnHg1mFbqgDhAAbwaQVkyKPmrvazh6/RCfTg== # 客户端通过映射mon节点6789端口进行挂载,同时传入用户名和密钥参数 # 挂载命令格式:mount -t ceph <MON节点1>:6789,<MON节点2>:6789,<MON节点3>:6789:/ <本地挂载点目录> -o name=<用户名>,secret=<秘钥> mount -t ceph 172.16.30.141:6789:/ /mnt/test/ -o name=admin,secret=AQAFGkRnUcLhMxAAoS/VJjhvvwd+kqVhL8ZrUQ== [root@huggingface-cli ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/centos-root 70G 21G 50G 30% / devtmpfs 7.8G 0 7.8G 0% /dev tmpfs 7.8G 0 7.8G 0% /dev/shm tmpfs 7.8G 805M 7.0G 11% /run tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup /dev/vda1 1014M 148M 867M 15% /boot tmpfs 1.6G 0 1.6G 0% /run/user/0 172.16.30.141:6789:/ 36G 0 36G 0% /mnt/test # 挂载成功
可视化面板
Ceph-Dashboard
在mgr节点安装
yum install ceph-mgr-dashboard -y开启dashborad模块
ceph mgr module enable dashboard关闭SSL
ceph config set mgr mgr/dashboard/ssl false监听IP+Port
ceph config set mgr mgr/dashboard/server_addr 0.0.0.0 ceph config set mgr mgr/dashboard/server_port 7001设置初始密码
echo "123456" > password.txt ceph dashboard ac-user-create admin administrator -i password.txt重启服务
ceph mgr module disable dashboard ceph mgr module enable dashboard # 查看服务 ceph mgr services { "dashboard": "http://ceph01:7001/" }访问
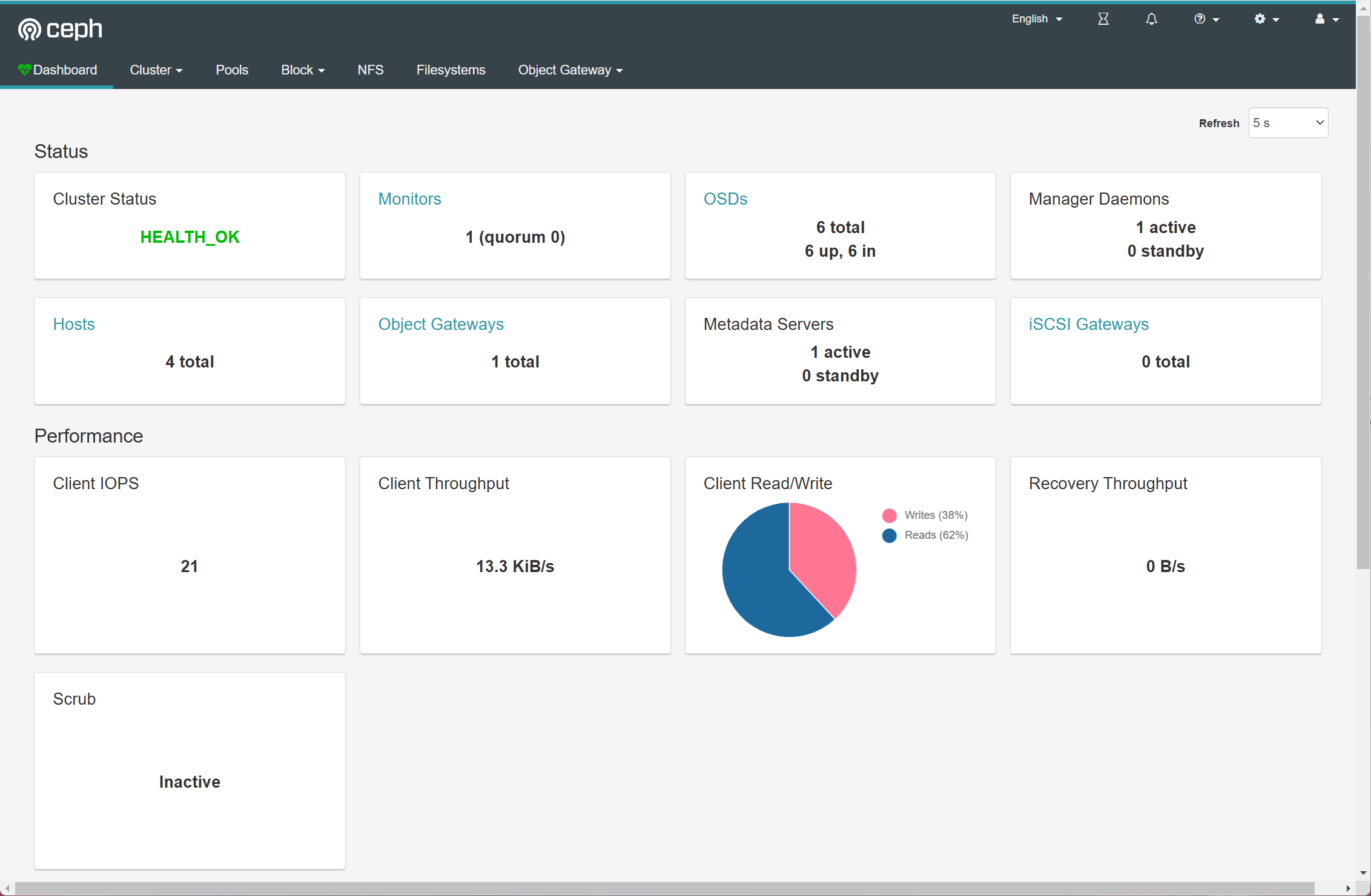
后续维护
OSD横向扩容
横向扩容即添加更多的OSD节点实现扩容
1.新节点系统环境准备(参考部署准备,直至免密登录步骤结束)
2.管理节点初始化OSD节点,擦除磁盘,添加OSD磁盘
为避免数据平衡在业务高峰时间造成性能影响,可以选择临时关闭自动同步
# 在初始化OSD节点前执行,关闭自动同步 ceph osd set norebalance ceph osd set norecover ceph osd set noin ceph osd set nobackfill # 在业务低峰时,开启自动同步 ceph osd unset norebalance ceph osd unset norecover ceph osd unset noin ceph osd unset nobackfill
OSD纵向扩容
纵向扩容即在现有的OSD节点中添加硬盘实现扩容
添加硬盘,擦除数据
扩容OSD
# 扩容前OSD拓扑 [root@ceph01 ceph]# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.05846 root default -3 0.01949 host ceph02 0 hdd 0.01949 osd.0 up 1.00000 1.00000 -5 0.01949 host ceph03 1 hdd 0.01949 osd.1 up 1.00000 1.00000 -7 0.01949 host ceph04 2 hdd 0.01949 osd.2 up 1.00000 1.00000 # 逐个节点逐个硬盘添加OSD ceph-deploy --overwrite-conf osd create ceph02 --data /dev/sdc ceph-deploy --overwrite-conf osd create ceph03 --data /dev/sdc ceph-deploy --overwrite-conf osd create ceph04 --data /dev/sdc # 扩容完成 [root@ceph01 ceph]# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -1 0.11691 root default -3 0.03897 host ceph02 0 hdd 0.01949 osd.0 up 1.00000 1.00000 3 hdd 0.01949 osd.3 up 1.00000 1.00000 -5 0.03897 host ceph03 1 hdd 0.01949 osd.1 up 1.00000 1.00000 4 hdd 0.01949 osd.4 up 1.00000 1.00000 -7 0.03897 host ceph04 2 hdd 0.01949 osd.2 up 1.00000 1.00000 5 hdd 0.01949 osd.5 up 1.00000 1.00000
剔除OSD节点
#查看osd的ID(管理节点执行)
ceph osd tree
#停用设备(管理节点执行)
ceph osd out {osd-num}
#停止进程(OSD节点执行)
systemctl stop ceph-osd@{osd-num}
#移除单个OSD设备(管理节点执行)
ceph osd purge {osd-num} --yes-i-really-mean-it
#移除整个节点:将节点上所有OSD都卸载后执行以下命令(管理节点执行)
ceph osd crush remove ceph{ID}附
(GPT)Ceph与主流存储服务(NFS、MinIO、HDFS)的横向对比
1. NFS
简介: NFS 是一种分布式文件系统协议,通过网络让多个客户端共享文件。常用于小型局域网环境中。
优点:
易于部署和使用,支持多种操作系统。
适合低复杂性场景,例如共享文档和简单的网络存储。
缺点:
性能有限,不适合大规模并发访问。
单点故障风险高,需要额外的高可用性解决方案。
数据一致性和并发性能较差,扩展性不足。
与 Ceph 对比:
Ceph 的优势:
无单点故障问题,天然支持高可用性。
分布式架构,支持大规模并发和横向扩展。
提供对象、块和文件三种存储方式,更灵活。
2. MinIO
简介: MinIO 是一个开源的高性能对象存储,兼容 S3 协议,专注于云原生环境。
优点:
轻量化设计,部署简单。
支持云原生架构,性能优越。
与 S3 协议高度兼容,适用于现代云存储需求。
缺点:
主要专注于对象存储,不支持块存储或文件存储。
对非常复杂的分布式场景支持较弱。
与 Ceph 对比:
Ceph 的优势:
Ceph 提供三种存储模式,应用场景更加广泛。
Ceph 的分布式架构更加成熟,适用于大规模企业级存储需求。
数据容灾能力更强,支持多副本和纠删码策略。
3. HDFS
简介: HDFS 是 Hadoop 的分布式文件系统组件,设计用于处理大数据分析任务中的海量数据。
优点:
针对大文件和大数据分析场景优化,吞吐量高。
与 Hadoop 生态深度集成,适合数据挖掘和分析工作流。
缺点:
高延迟,不适合小文件和低延迟访问需求。
主要服务于离线批处理场景,实时性较差。
缺乏块存储和对象存储支持,使用场景局限。
与 Ceph 对比:
Ceph 的优势:
Ceph 适合在线应用场景,延迟低。
同时支持块、文件和对象存储,可以覆盖更多使用场景。
更加灵活,适合多种 IT 基础设施,不依赖特定生态系统。
参考资料
https://documentation.suse.com/zh-cn/ses/7.1/html/ses-all/storage-bp-hwreq.html
https://www.cnblogs.com/liujitao79/p/15237657.html
https://www.cnblogs.com/fsdstudy/p/18206169
https://www.yuandangsheng.top/?p=3634
https://blog.csdn.net/weixin_44923267/article/details/137560926