Prometheus监控NvidiaGPU集群
故事背景:公司机房新进GPU集群,研发要求监控每个GPU利用率用来调度训练任务,历时数小时,通过nvidia-gpu-exporter接入现有的Prometheus平台实现,以下是实现过程。
指标采集使用该项目实现:https://github.com/utkuozdemir/nvidia_gpu_exporter
1. 单机部署
安装探针
$ cd /opt
$ VERSION=1.2.0
$ wget https://github.com/utkuozdemir/nvidia_gpu_exporter/releases/download/${VERSION}/nvidia-gpu-exporter_${VERSION}_linux_amd64.rpm
$ rpm -ivh nvidia_gpu_exporter_${VERSION}_linux_amd64.rpm
$ nvidia_gpu_exporter
ts=2023-09-13T09:43:32.819Z caller=tls_config.go:232 level=info msg="Listening on" address=[::]:9835
ts=2023-09-13T09:43:32.820Z caller=tls_config.go:235 level=info msg="TLS is disabled." http2=false address=[::]:9835测试指标
[root@SSHVL014 prometheus]# curl http://172.16.0.40:9835/metrics
# .........
# HELP nvidia_gpu_exporter_build_info A metric with a constant '1' value labeled by version, revision, branch, goversion from which nvidia_gpu_exporter was built, and the goos and goarch for the build.
# TYPE nvidia_gpu_exporter_build_info gauge
nvidia_gpu_exporter_build_info{branch="HEAD",goarch="amd64",goos="linux",goversion="go1.20",revision="01f163635ca74aefcfb62cab4dc0d25cc26c0562",version="1.2.0"} 1
# HELP nvidia_smi_accounting_buffer_size accounting.buffer_size
# TYPE nvidia_smi_accounting_buffer_size gauge
nvidia_smi_accounting_buffer_size{uuid="0892cf79-3fec-e043-a7f6-a237215f0f19"} 4000
nvidia_smi_accounting_buffer_size{uuid="2cfa94f3-d106-974e-57ef-1a2cb0b512f8"} 4000
nvidia_smi_accounting_buffer_size{uuid="f3e8047a-cc6e-bc4c-0b6b-454ca14d85ff"} 4000
# .........
可以看到指标已经上线,下面接入prometheus进行采集
接入Prometheus
修改prometheus配置文件
- job_name: 'nvidia_gpu_exporter'
scrape_interval: 15s
scrape_timeout: 10s
metrics_path: /metrics
file_sd_configs:
- files:
- './nodes/nvidia_gpu_nodes.yml'- targets:
- 172.16.0.40:9835
labels:
location: 'gpu_nodes'Grafana面板展示
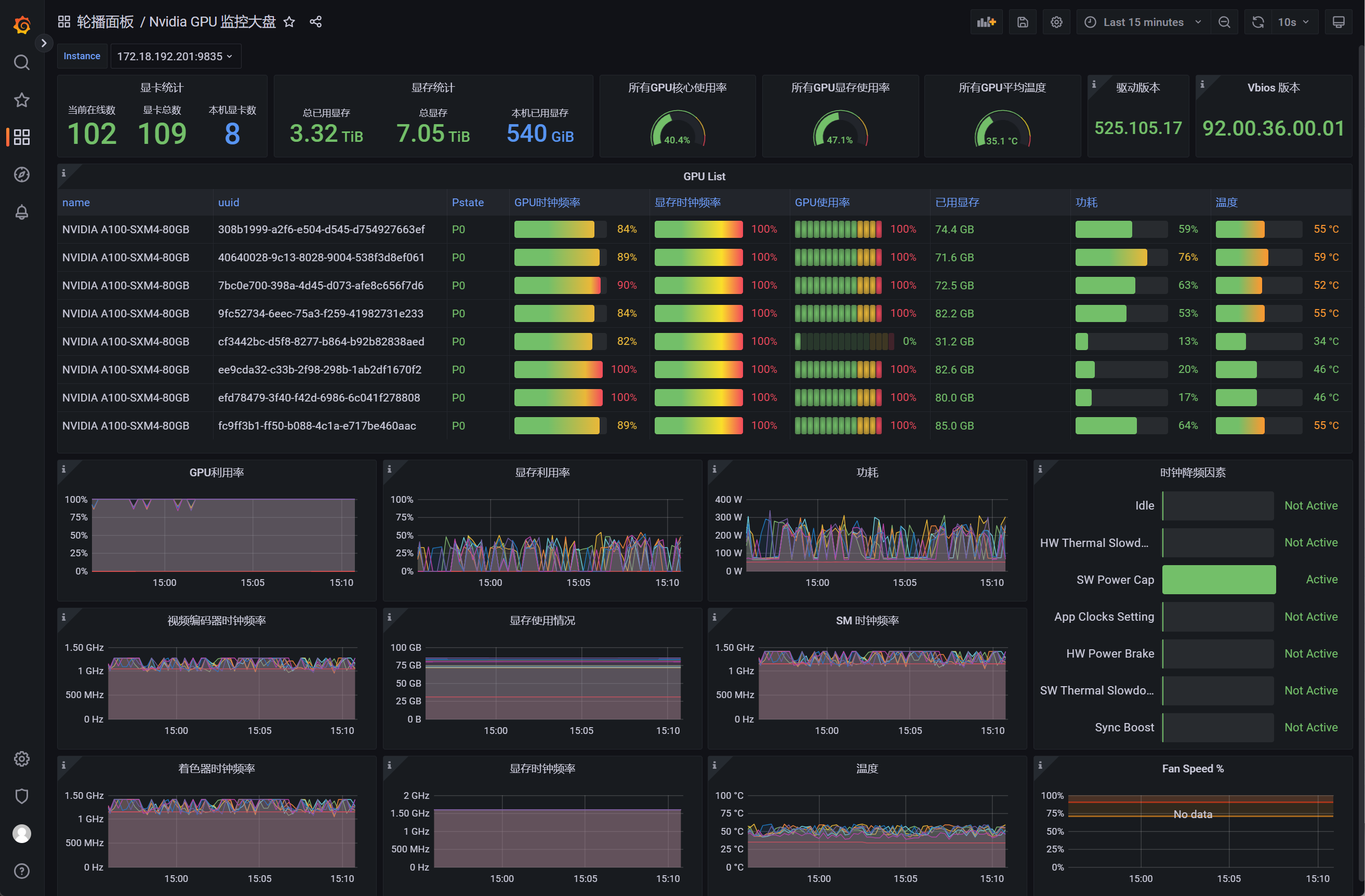
导入项目官方面板查看效果,稍候我们将进一步修改面板以实现集群监控
 单机需求实现,下面开始部署到整个集群。
单机需求实现,下面开始部署到整个集群。
2. 集群部署
集群部署主要利用ansible实现,由于探针使用rpm安装,所以整个过程比较简单,以下是playbook内容
---
- name: Install nvidia-gpu-exporter RPM
hosts: gpu_nodes
become: true
gather_facts: false
tasks:
- name: Copy RPM package to remote host
copy:
src: /etc/ansible/packages/nvidia-gpu-exporter_1.2.0_linux_amd64.rpm
dest: /tmp/nvidia-gpu-exporter_1.2.0_linux_amd64.rpm
- name: Install RPM package
yum:
name: /tmp/nvidia-gpu-exporter_1.2.0_linux_amd64.rpm
state: present编排好集群节点,开始部署安装
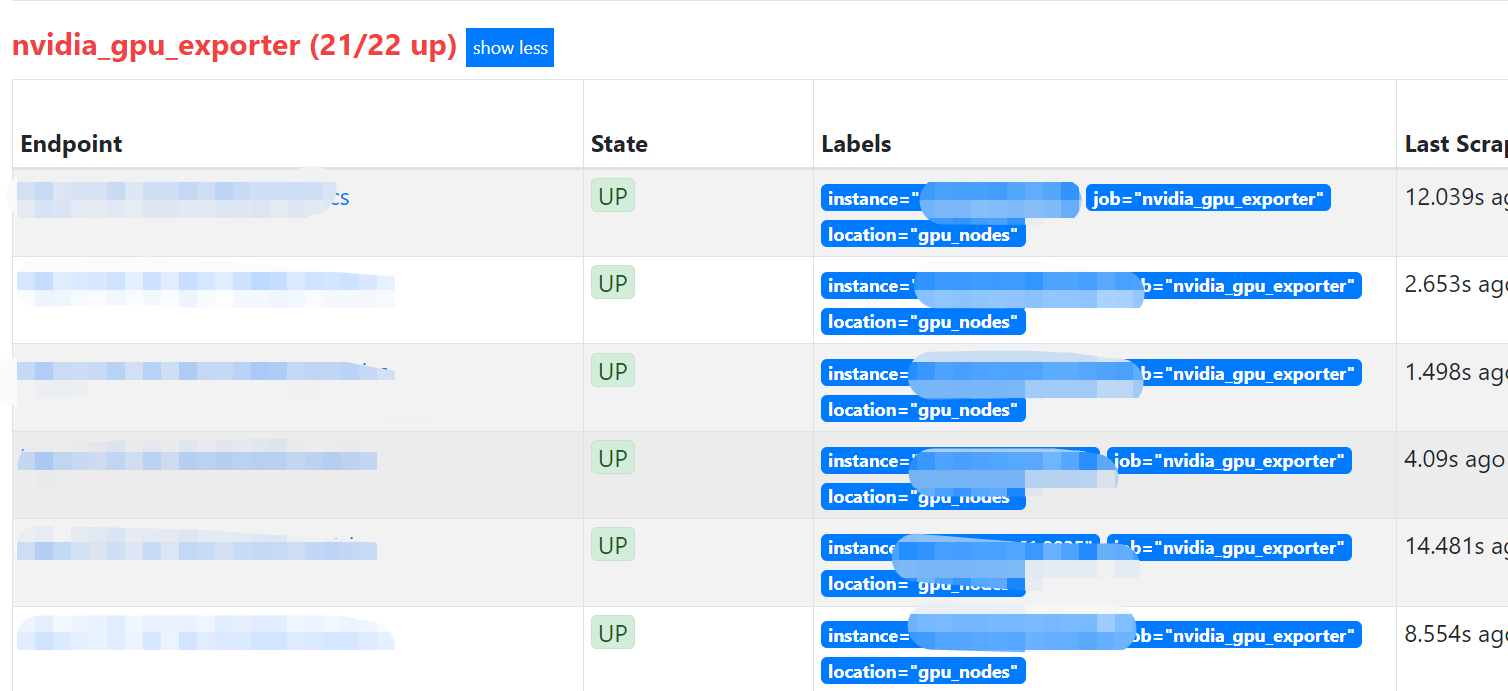
[root@sshvl032 ansible]# ansible-playbook roles/nvidia-gpu-exporter.yml -i gpu_nodes安装完毕,更新prometheus中的nvidia_gpu_nodes.yml,将节点全部添加进去,prometheus将自动发现目标进行采集
3. 编写面板
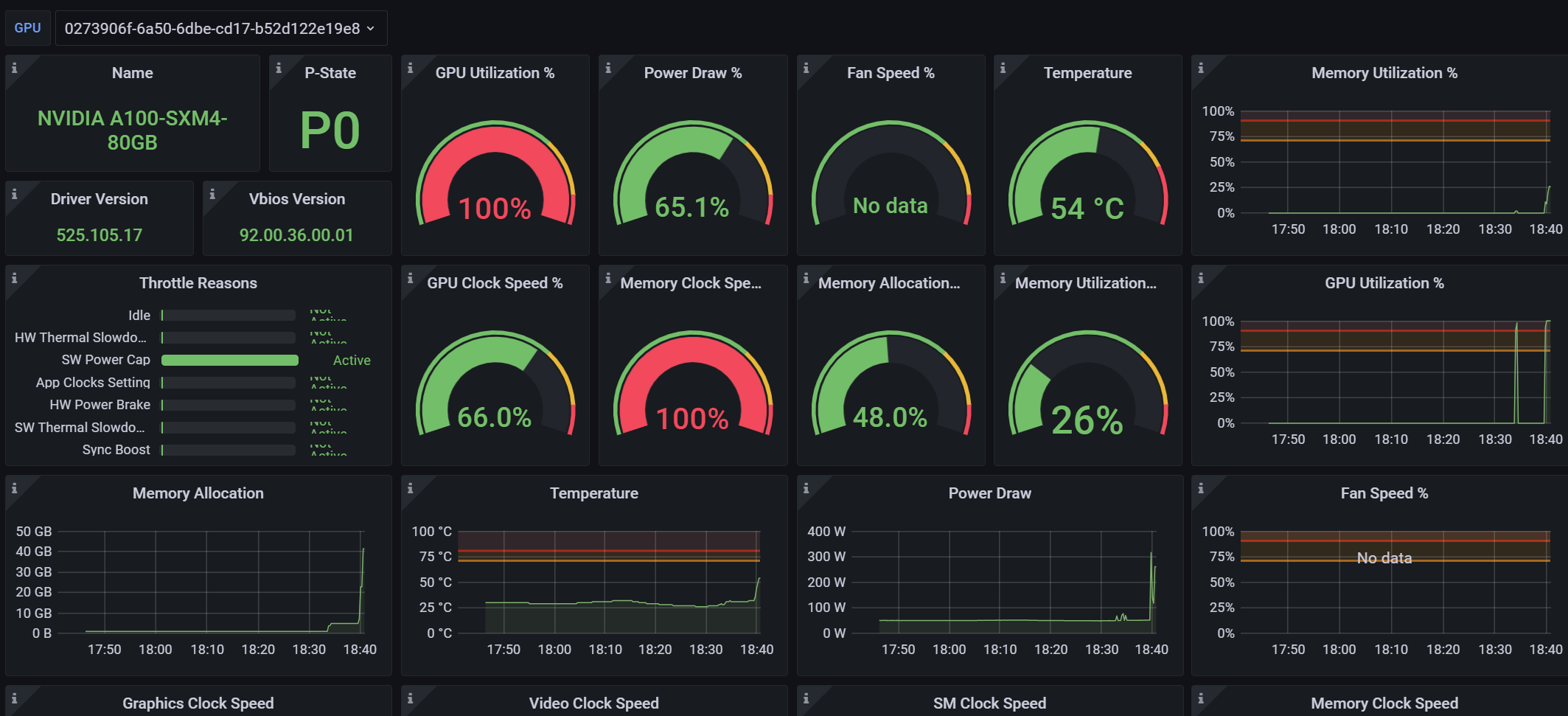
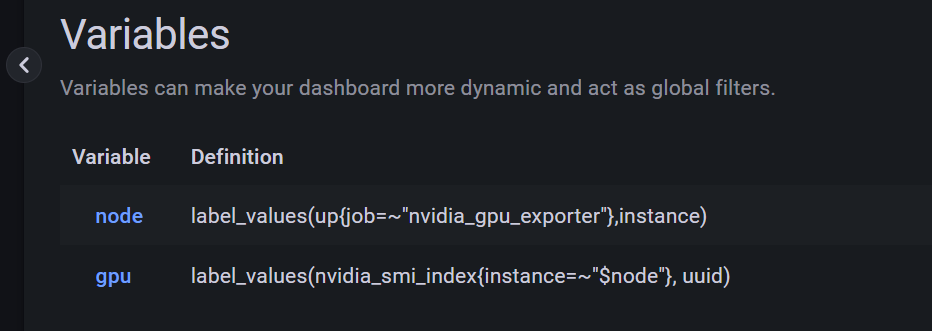
由于默认面板是以GPU为单位展示数据,而我们集群管理肯定希望以node展示,所以首先增加node全局变量,其次根据node列出对应gpu
然后我们需要列出node下的所有GPU信息,下面创建一个表格panel
获取GPU型号与uuid对照信息,使用Transform中的Organize fields隐藏掉不需要的字段
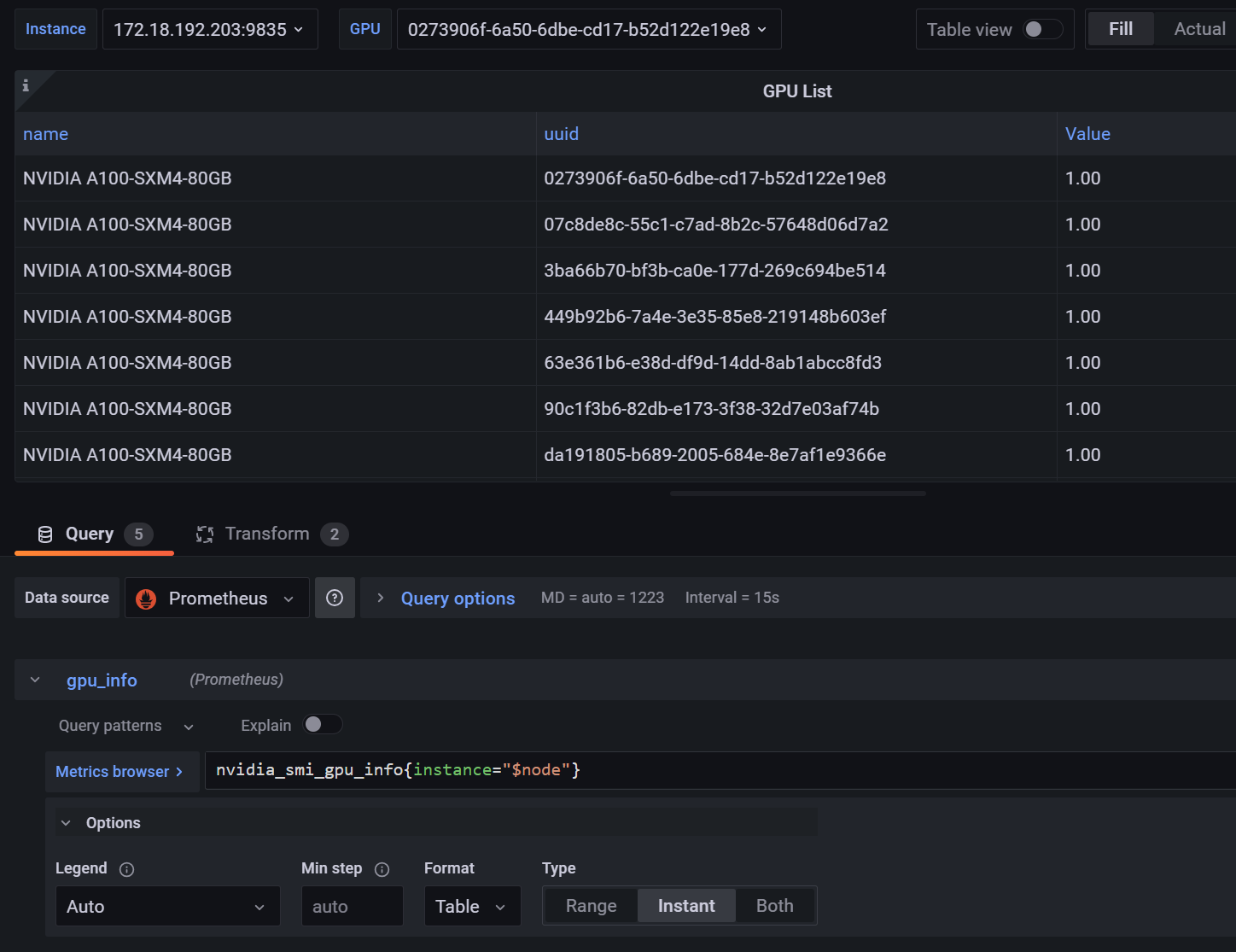
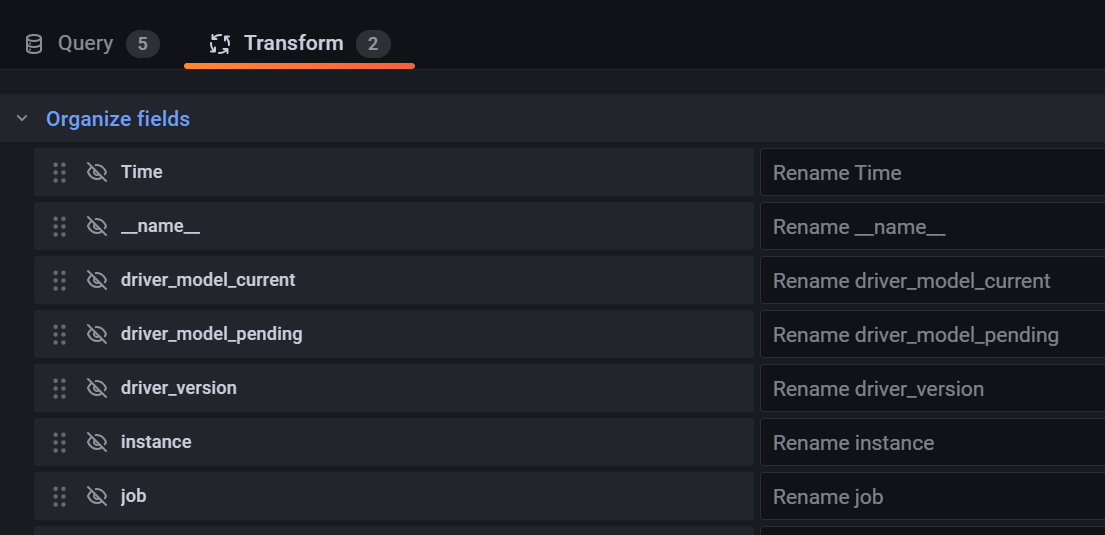
接下来新建数据列,扩展指标,并在Transform中创建Merge用于合并指标到表格中
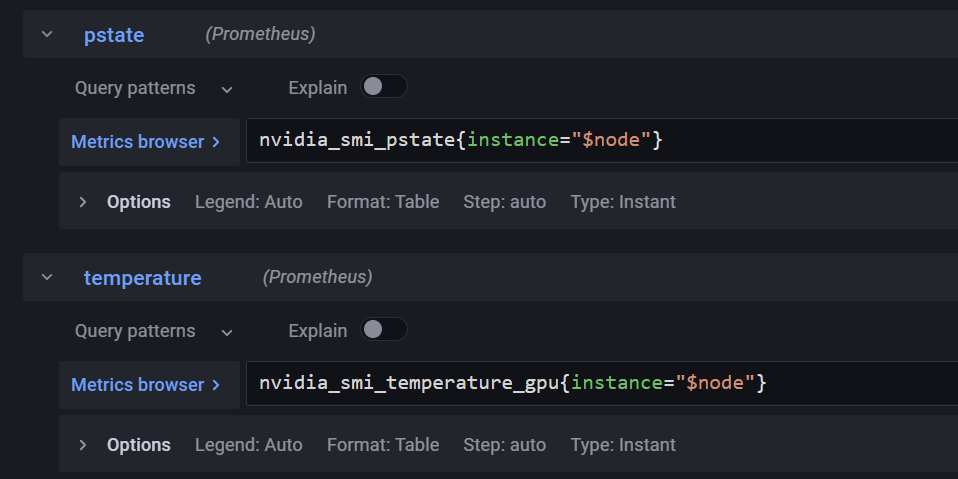
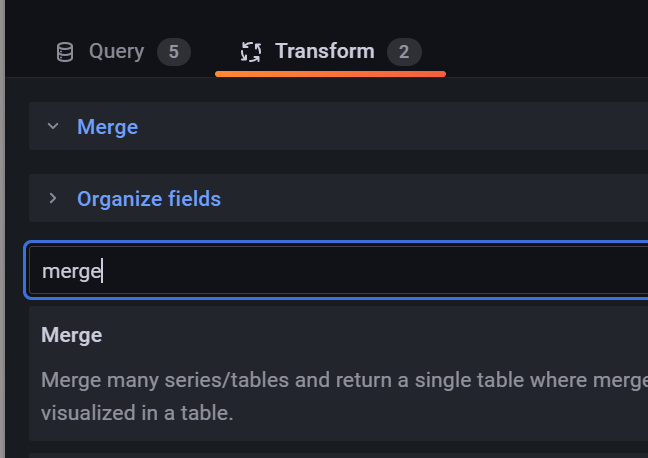
逐个添加指标后,使用Override重写每个数据列的数据格式以及展示样式
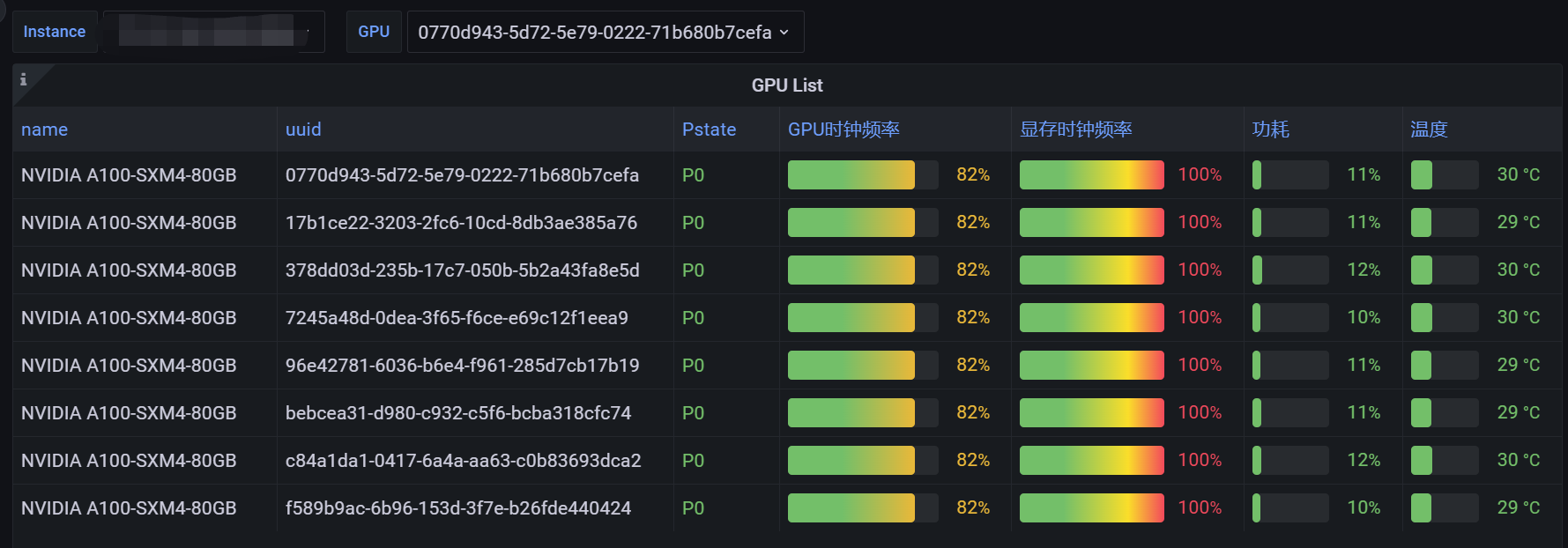
最终效果如下: