深入理解Kubernetes Pod创建过程
Pod是Kubernets集群中的最小调度单元,其中包含容器、存储、网络、元数据与环境变量等数据,由这些数据构成我们创建的应用实例。那么Pod是如何被创建出来的呢?本次内容我们来了解一下Pod的生命周期。
在开始之前,我们要先理解Kubernetes中的几大核心组件和作用,这对熟悉整个流程至关重要。
一、Kubernetes组件架构介绍
Kubernetes组件架构图
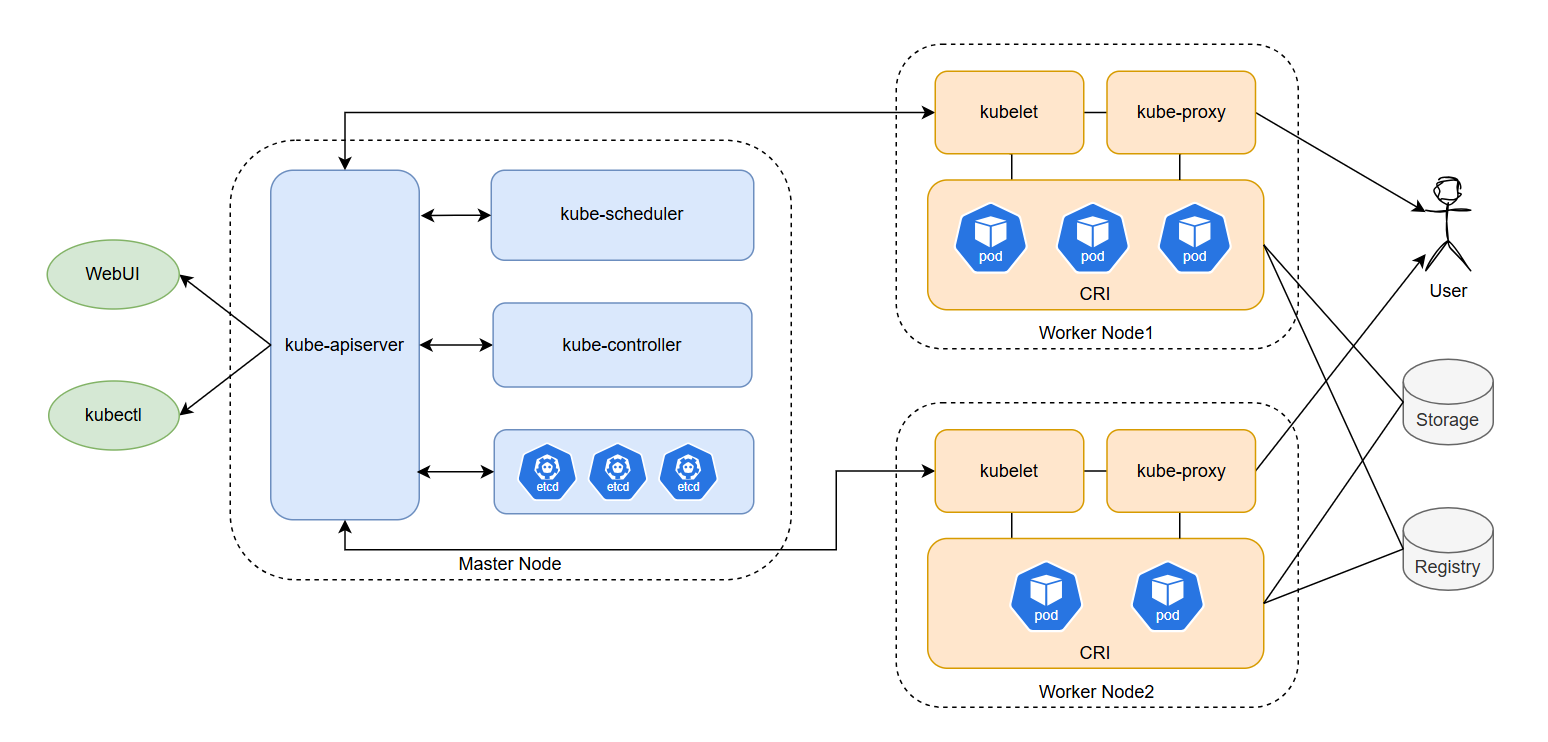
控制平面组件
控制平面(蓝色区域)负责整个集群的管理和调度工作,主要运行在主节点(Master Node)上。
kube-apiserver:核心API服务器,提供RESTful API接口,处理用户和组件的请求,是集群中各个组件交互的核心枢纽。
etcd:分布式高性能键值存储服务,用于保存集群的所有数据,例如配置、状态等。
kube-scheduler:调度器,负责把业务容器调度到最合适的工作节点。
kube-controller-manager:集群控制器管理,控制器用来维护集群各个组件工作所需的状态。常见控制器有:
节点控制器:监控节点状态,在节点异常时执行回收和重新调度操作。
副本控制器:维护Pod副本数符合期望,确保可靠性。
服务控制器:管理负载均衡器。
账户控制器:为Pod创建服务账户和API访问令牌。
等等....
节点平面组件
节点组件(橙色区域)运行在每个工作节点(Worker Node)上,负责管理本节点的容器运行和通信。
kubelet:运行在每个节点的代理程序
pod管理:kubelet从APIserver获取该节点所需容器清单和配置明细,然后向容器平台下发创建/关闭等命令。
容器健康检查:kubelet在创建容器后还需要确保容器的健康状态,如果容器出错,则根据pod设置的重启策略进行处理。
容器监控:kubelet会监控所在节点的资源和运行情况,并定期向APIserver汇报。
CRI(Container Runtime Interface):插件接口,负责与各种容器Runtime进行通信,例如Docker、Containerd。
kube-proxy:维护节点中的iptables或ipvs规则,根据Service定义管理集群内部或外部与Pod通信。
除此之外还有其他附加组件,例如cloud-controller-manager、DNS、Dashboard等,在这里不做过多介绍,有兴趣可查阅K8S文档。
二、List-Watch机制
在了解完组件后,我们还需要了解一下Kubernetes最重要的工作模式:List-Watch
List-Watch 模式是Kubernetes 中一种常见的模式,controller-manager,scheduler,kubelet都采取List-Watch模式与kube-apiserver通信,以便实时监控资源的变化。这种模式结合了列表 (List) 和观察 (Watch) 两种操作,允许组件在 Kubernetes API server 中的资源发生变化时获得通知。从而实现每个组件的协作,保持数据同步,每个组件之间的设计实现了解耦。
List:当组件首次启动或重新同步时,它会调用List操作,从apiserver获取其所关心的资源当前状态的完整列表,例如,ReplicaSet 控制器可能会获取所有的 ReplicaSet 资源。
Watch:列表操作完成后,组件开始Watch操作,它会和apiserver建立一个长连接,等待apiserver发送有关资源变更的通知(例如新建、删除、更新),这样组件可以实时获知资源状态的变化,并根据需要做出反应。
三、Kubernetes Pod创建过程
典型Pod创建流程时序图
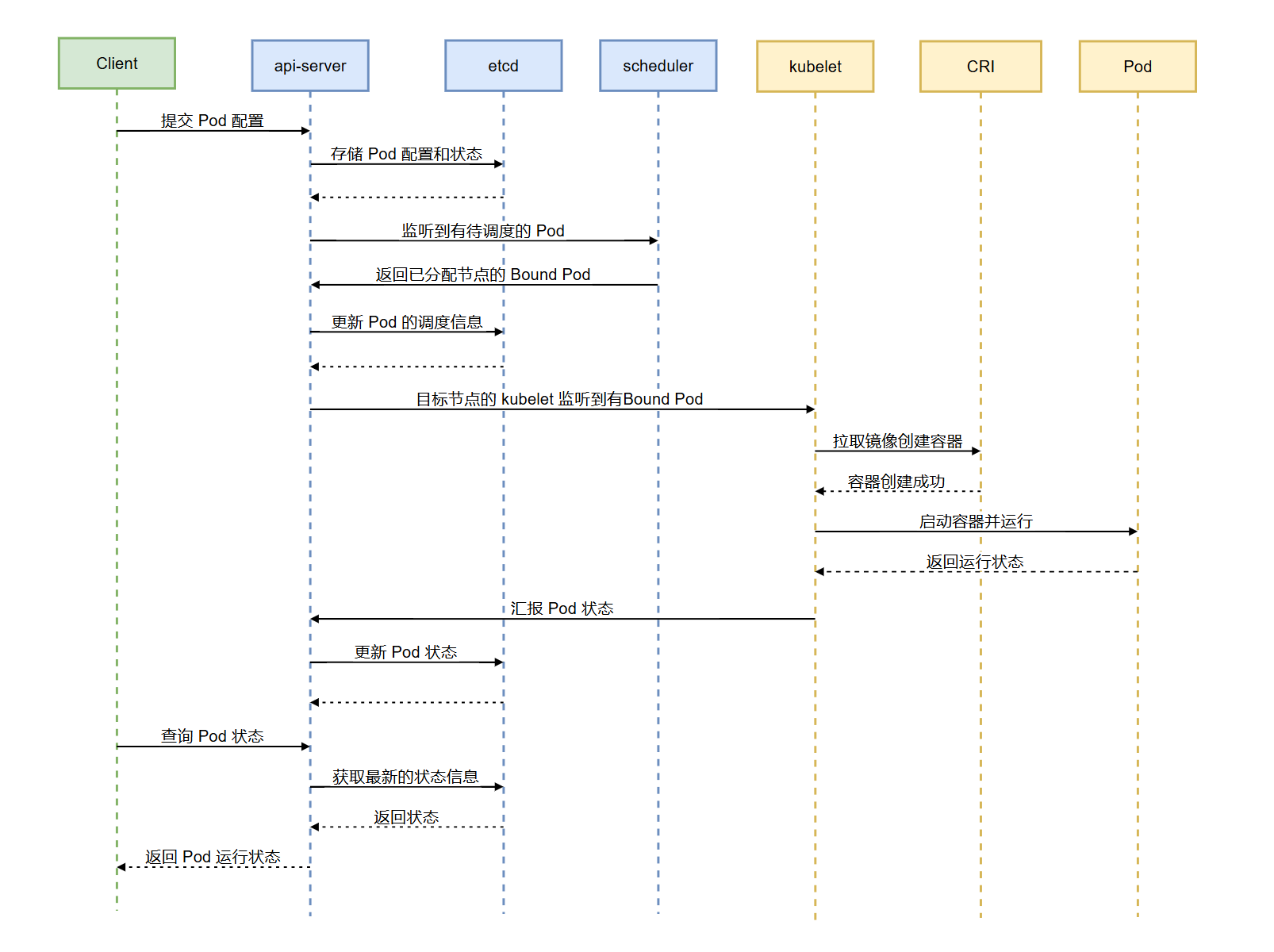
典型Pod创建流程描述
用户通过 kubectl或API,向 kube-apiserver 提交 Pod 创建请求和yaml配置文件。
kube-apiserver在接收用户请求后,首先会验证用户的身份和权限,鉴权通过后检查配置文件(例如yaml格式)。
kube-apiserver将 Pod 的配置信息存储到 etcd 中,并记录为
Pending状态,这是第一次写etcd动作。kube-scheduler 通过List-Watch机制监听到有未调度的 Pod,向apiserver请求Pod信息,当scheduler发现Pod属性中Dest Node为空时(Dest Node =""),便会立即触发调度流程进行调度。
kube-scheduler调度完成后,会进行binding操作,同时将调度结果返回给api-server并存储到etcd中,Pod 的状态从
Pending更新为Scheduled,这是第二次写etcd动作。kubelet通过List-Watch机制监听获取当前节点需要运行的所有Pod。
kubelet通过CRI通知容器运行时(例如Docker)需要创建Pod,Docker在接收到配置信息后开始拉取镜像,创建容器。
CRI启动容器后告知kubelet当前Pod状态,kubelet会定期将状态信息汇报给apiserver。
kube-apiserver 将 Pod 的最新状态(如
Running、CrashLoopBackOff)更新到 etcd,这是第三次写etcd。用户通过
kubectl get pod查看 Pod 的状态。kube-apiserver 从 etcd 获取最新的状态信息并返回给用户。
至此,Pod创建完成。
四、Kube-Scheduler调度过程
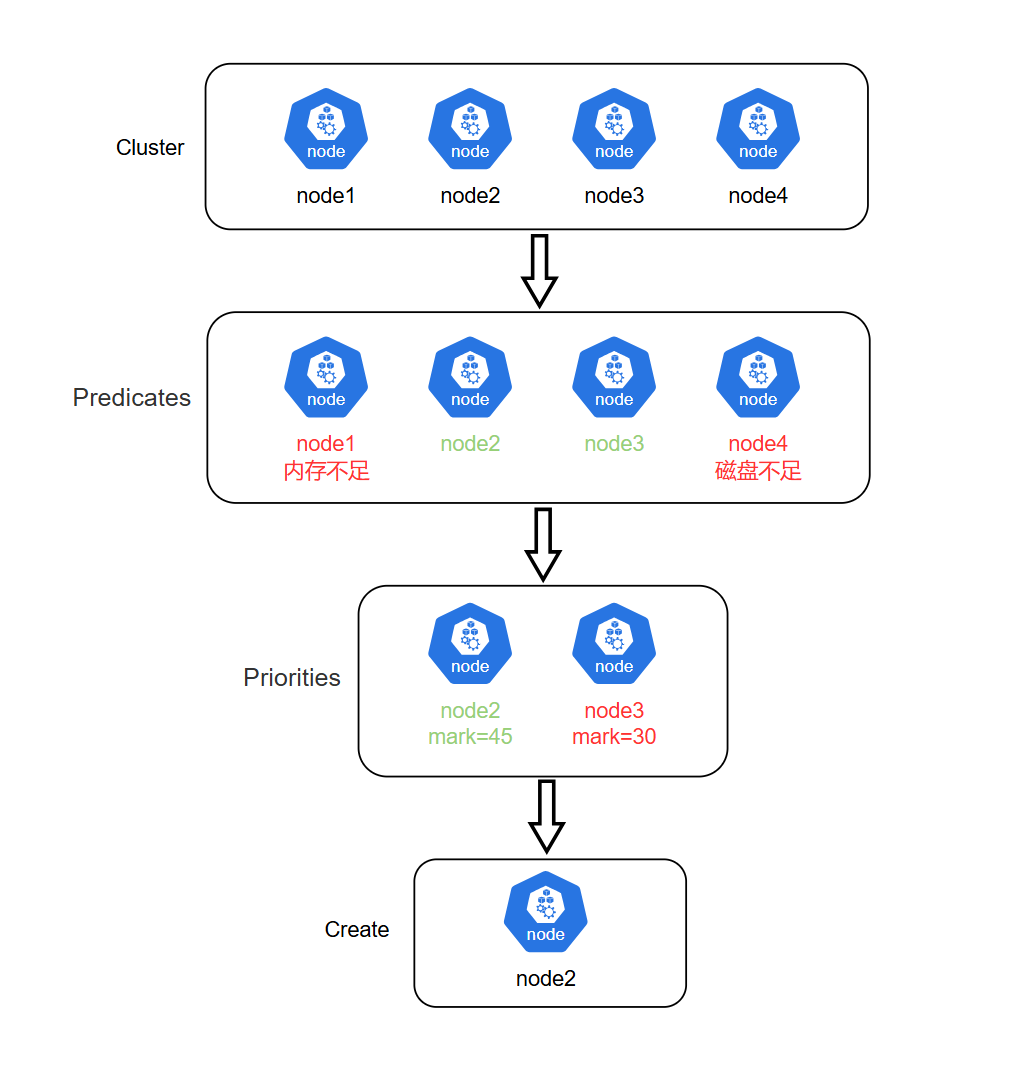
上面我们提到了scheduler对Pod进行调度,将Pod分配到最适合的节点,那么scheduler是如何知道哪个节点是否合适呢,下面来了解一下scheduler的调度原理。
scheduler调度过程主要分为两个步骤:
1.过滤(Predicates 预选策略):过滤阶段会将所有满足 Pod 调度需求的 Node 选出来。例如,PodFitsResources 过滤函数会检查候选 Node 的可用资源能否满足 Pod 的资源请求。在过滤之后,得出一个 Node 列表,里面包含了所有可调度节点;通常情况下,这个 Node 列表包含不止一个 Node。如果这个列表是空的,代表这个 Pod 不可调度。
2.打分(Priorities 优选策略):在过滤阶段后调度器会为 Pod 从所有可调度节点中选取一个最合适的 Node。根据当前启用的打分规则,调度器会给每一个可调度节点进行打分。最后,kube-scheduler 会将 Pod 调度到得分最高的 Node 上。如果存在多个得分最高的 Node,kube-scheduler 会从中随机选取一个。
整体流程如下图所示:
过滤策略:
1.PodFitsHostPorts:检查Node上是否不存在当前被调度Pod的端口(如果被调度Pod用的端口已被占用,则此Node被Pass)。
2.PodFitsHost:检查Pod是否通过主机名指定了特性的Node (是否在Pod中定义了nodeName)
3.PodFitsResources:检查Node是否有空闲资源(如CPU和内存)以满足Pod的需求。
4.PodMatchNodeSelector:检查Pod是否通过节点选择器选择了特定的Node (是否在Pod中定义了nodeSelector)。
5.NoVolumeZoneConflict:检查Pod请求的卷在Node上是否可用 (不可用的Node被Pass)。
6.NoDiskConflict:根据Pod请求的卷和已挂载的卷,检查Pod是否合适于某个Node (例如Pod要挂载/data到容器中,Node上/data/已经被其它Pod挂载,那么此Pod则不适合此Node)
7.MaxCSIVolumeCount::决定应该附加多少CSI卷,以及是否超过了配置的限制。
8.CheckNodeMemoryPressure:对于内存有压力的Node,则不会被调度Pod。
9.CheckNodePIDPressure:对于进程ID不足的Node,则不会调度Pod
10.CheckNodeDiskPressure:对于磁盘存储已满或者接近满的Node,则不会调度Pod。
11.CheckNodeCondition:Node报告给API Server说自己文件系统不足,网络有写问题或者kubelet还没有准备好运行Pods等问题,则不会调度Pod。
12.PodToleratesNodeTaints:检查Pod的容忍度是否能承受被打上污点的Node。
13.CheckVolumeBinding:根据一个Pod并发流量来评估它是否合适(这适用于结合型和非结合型PVCs)。
打分策略:
1.SelectorSpreadPriority:优先减少节点上属于同一个 Service 或 Replication Controller 的 Pod 数量
2.InterPodAffinityPriority:优先将 Pod 调度到相同的拓扑上(如同一个节点、Rack、Zone 等)
3.LeastRequestedPriority:节点上放置的Pod越多,这些Pod使用的资源越多,这个Node给出的打分就越低,所以优先调度到Pod少及资源使用少的节点上。
4.MostRequestedPriority:尽量调度到已经使用过的 Node 上,将把计划的Pods放到运行整个工作负载所需的最小节点数量上。
5.RequestedToCapacityRatioPriority:使用默认资源评分函数形状创建基于requestedToCapacity的 ResourceAllocationPriority。
6.BalancedResourceAllocation:优先平衡各节点的资源使用。
7.NodePreferAvoidPodsPriority:根据节点注释对节点进行优先级排序,以使用它来提示两个不同的 Pod 不应在同一节点上运行。 scheduler.alpha.kubernetes.io/preferAvoidPods。
8.NodeAffinityPriority:优先调度到匹配 NodeAffinity (Node亲和性调度)的节点上。
9.TaintTolerationPriority:优先调度到匹配 TaintToleration (污点) 的节点上
10.ImageLocalityPriority:尽量将使用大镜像的容器调度到已经下拉了该镜像的节点上。
11.ServiceSpreadingPriority:尽量将同一个 service 的 Pod 分布到不同节点上,服务对单个节点故障更具弹性。
12.EqualPriority:将所有节点的权重设置为 1。
13.EvenPodsSpreadPriority:实现首选pod拓扑扩展约束。
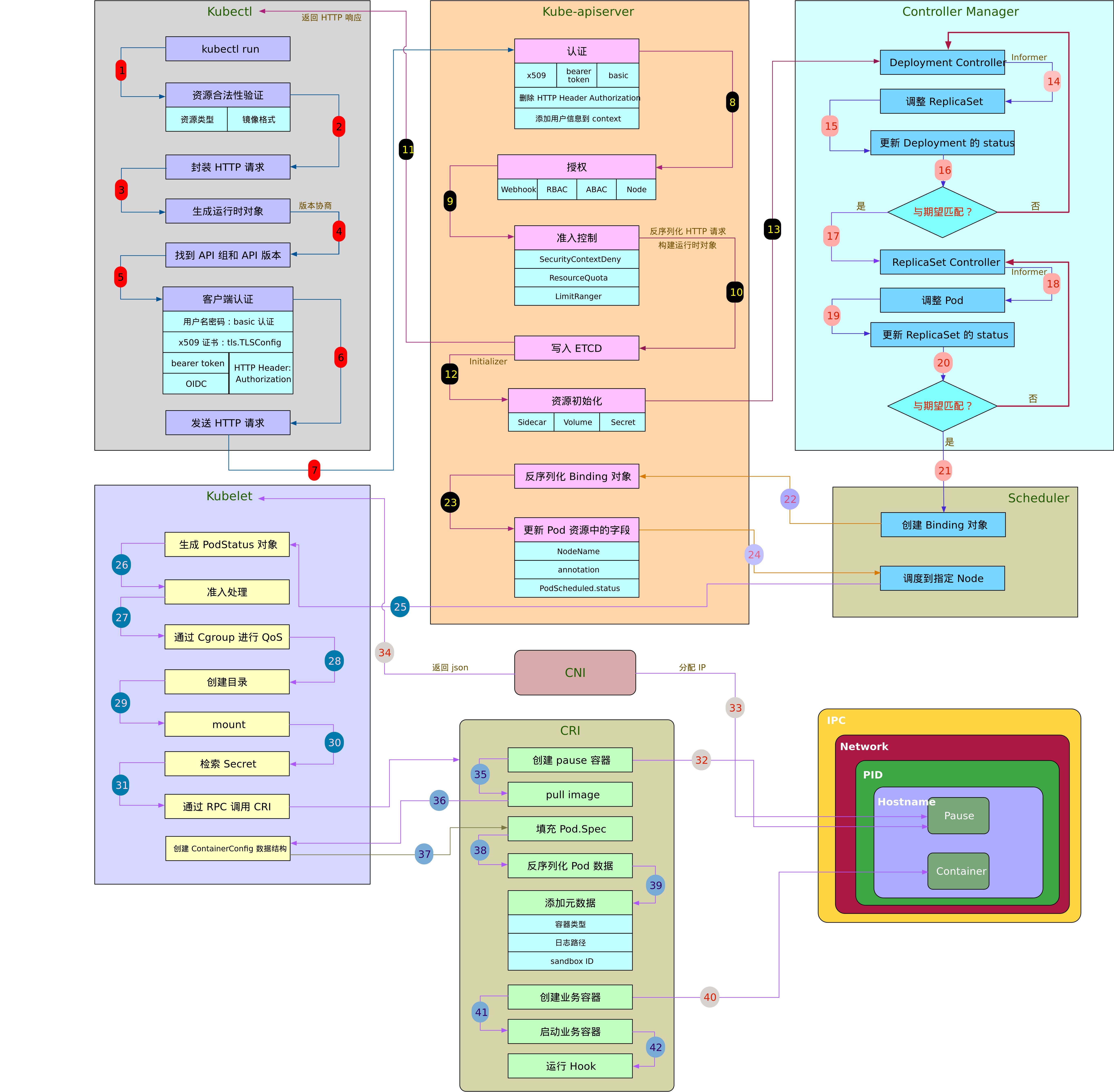
本文主要是依个人理解而论的简化版流程,实际Kubernetes新建一个资源的过程十分复杂,如果想了解更多可以结合K8S源码和下面的流程图尝试理解具体组件的原理:
参考资料:
https://kubernetes.io/zh-cn/docs/concepts/architecture/
https://blog.csdn.net/weixin_46660849/article/details/133840064